10 مورد از الگوریتم های یادگیری ماشین که باید بشناسید

امروزه، که تجزیه و تحلیل داده ها، قدرت محاسباتی بزرگ و محاسبات ابری توسعه یافته است، الگوریتم های یادگیری ماشین نقش مهمی را ایفا می کنند. به همین دلیل اگر به حوزه هوش مصنوعی به خصوص ماشین لرنینگ علاقه دارید، باید با مهمترین الگوریتم های یادگیری ماشین آشنا شوید. در ادامه 10 مورد از الگوریتم های یادگیری ماشین را معرفی می کنیم. اگر تمایل دارید به جهانی از دانش و تخصص در حوزه هوش مصنوعی وارد شوید، با پیوستن به آکادمی تخصصی هوش مصنوعی مهسا می توانید با علاقه مندان و متخصصان این حوزه آشنا شوید.
دسته های الگوریتم یادگیری ماشین
الگوریتم های یادگیری ماشین مجموعهای از روشها و الگوریتمهای کامپیوتری هستند که به ماشینها و سیستمهای کامپیوتری اجازه میدهند که از تجربه (دادهها) یاد بگیرند و عملکرد خود را بهبود دهند. هدف اصلی این الگوریتمها، ایجاد مدلها و قوانینی است که بتوانند الگوها و ویژگیهای مختلف موجود در دادهها را شناسایی کنند و از آنها برای پیشبینی و تصمیمگیری استفاده کنند.
الگوریتمهای یادگیری ماشین به دو دستهبندی اصلی تقسیم میشوند:
- یادگیری نظارتشده (Supervised Learning): در این دسته از الگوریتمها، دادههای آموزشی که دارای ویژگیها و برچسبهای مشخص هستند به ماشین ارائه میشوند. هدف این الگوریتمها این است که با توجه به ویژگیها، برچسبها و پارامترهایی که بهینهسازی میشوند، مدلی بسازند که بتواند به درستی برچسبها را برای دادههای جدید تخمین بزند. مثالهایی از الگوریتمهای این دسته عبارتند از رگرسیون خطی، ماشین بردار پشتیبان، و درخت تصمیم.
- یادگیری بدون نظارت (Unsupervised Learning): در این دسته از الگوریتمها، دادهها بدون برچسبها به ماشین داده میشوند. هدف این الگوریتمها این است که الگوها، ساختارها و تقارنهای مخفی در دادهها را شناسایی کنند. مثالهایی از الگوریتمهای این دسته شامل خوشهبندی، کاهش ابعاد، و تحلیل افتراقی نیست.
در طول سالها، بسیاری از الگوریتمهای یادگیری ماشین معرفی شدند. به طوری که به تدریج برای مسائل مختلف و با توجه به مشخصات دادهها مورد استفاده قرار میگیرند. این الگوریتمها در زمینههای مختلف از پزشکی و تشخیص بیماری تا مالی و تحلیل بازار سرمایه استفاده میشوند و نقش مهمی در پیشرفت تکنولوژی و تصمیمگیری هوش مصنوعی ایفا میکنند. در ادامه 10 مورد از مهمترین الگوریتم های یادگیری ماشین را معرفی میکنیم.
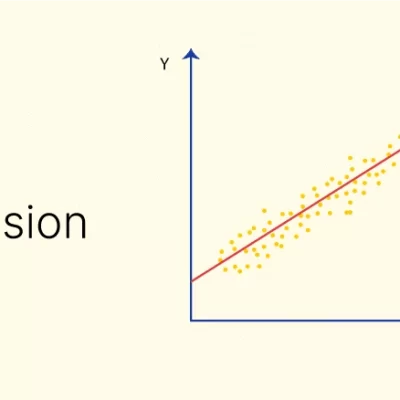
رگرسیون خطی از الگوریتم های یادگیری ماشین
الگوریتم رگرسیون خطی یکی از پرکاربردترین الگوریتم های یادگیری ماشین است. در این الگوریتم، تلاش میشود یک خط (یا همان رگرسیون خطی) پیدا کرد که بهترین تطابق را بین ویژگیهای ورودی و مقدار خروجی ایجاد کند. این خط، تلاش میکند تا خطای پیشبینیها را به حداقل برساند.
عملکرد رگرسیون خطی بر پایهی تطابق بین دادههای آموزشی و مدل خطی استوار است. با داشتن دادههای آموزشی که شامل ویژگیها و مقادیر خروجی مربوطه هستند، الگوریتم سعی میکند وزنها و ضرایب خط را به گونهای تنظیم کند که خطای پیشبینیها کمینه شود. در واقع، رگرسیون خطی مفهوم پایهای یادگیری ماشین را شکل میدهد و به خوبی در مواردی که رابطهی خطی بین ورودی و خروجی وجود دارد، عملکرد خوبی دارد.
الگوریتم ماشین بردار پشتیبان از الگوریتم های یادگیری ماشین
الگوریتم ماشین بردار پشتیبان (Support Vector Machine یا SVM) نیز یکی از محبوبترین و قدرتمندترین الگوریتم های یادگیری ماشین است. SVM به عنوان یک الگوریتم دستهبندی و رگرسیون عمل میکند. این الگوریتم برای مسائل مختلفی مانند دستهبندی تصویر، تشخیص نوع داده، تشخیص اسپم و مسائل پیشبینی کاربرد دارد.
هدف اصلی SVM ایجاد یک حاشیه (مرز) میان دستههای مختلف دادهها به نحوی که فاصله بین نقاط نزدیک به حاشیه واقع در دو دسته (نقاط پشتیبان) حداکثر و بهترین شود. در واقع، SVM به دنبال پیدا کردن بهترین مرز جداکننده بین دستههای دادهای است که در بعد بالاتر (در مورد چند بعدی) به عنوان “ماشین بردار” شناخته میشود. همچنین، SVM از تکنیکهای ریاضی پیچیدهتری استفاده میکند که به وسیلهی تبدیلهای هسته (Kernel) قادر به مدلسازی روابط غیرخطی نیز میشود. این به SVM امکان دستهبندی و رگرسیون در دادههایی که روابط خطی مشخصی ندارند، میدهد.
الگوریتم k نزدیک ترین همسایه از الگوریتم های یادگیری ماشین
الگوریتم k نزدیکترین همسایه (k-Nearest Neighbors یا k-NN) یک روش ساده و پرکاربرد در دستهبندی و پیشبینی در الگوریتم های یادگیری ماشین است. در این الگوریتم، برای پیشبینی دسته یا مقدار خروجی یک نقطه جدید، k نزدیکترین نقاط آموزشی به آن نقطه انتخاب میشوند. سپس با توجه به اکثریت دستههای نزدیکترین نقاط، دسته یا مقدار خروجی برای نقطه جدید تعیین میشود.
در این الگوریتم، k مقداری مثبت کوچک است که تعیین میکند که چه تعداد نزدیکترین همسایه برای تصمیمگیری باید در نظر بگیرید. با افزایش مقدار k، تأثیر نویز و دادههای پرت در تصمیمگیری کمتر میشود. الگوریتم k-NN به علت سادگی اجرایی و قابلیت مقابله با مسائل غیرخطی مورد استفاده قرار میگیرد. با این حال، در مجموعههای داده بزرگ، ممکن است عملکرد این الگوریتم با کارآیی پایین مواجه شود و به مدیریت مناسبی از دادهها نیاز باشد.
الگوریتم رگرسیون لجستیک از الگوریتم های یادگیری ماشین
الگوریتم رگرسیون لجستیک یکی از اصولیترین و پرکاربردترین الگوریتم های یادگیری ماشین است که برای مسائل دستهبندی به کار میرود. در واقع، این الگوریتم برای تخمین احتمال اینکه یک نمونه به یک دسته مشخص تعلق دارد یا نه، استفاده میشود.
علیرغم نام “رگرسیون” در اسم این الگوریتم، رگرسیون لجستیک در واقع یک مدل دستهبندی است که از تابع لجستیک برای تبدیل خروجیها به فضای احتمالی استفاده میکند. این تابع توانایی تبدیل اعداد ورودی (خروجی مدل قبل از تبدیل) به بازهی (0، 1) را دارد که معمولاً تفسیر احتمال تعلق به یک دسته را ایجاد میکند.
هدف اصلی این الگوریتم، یافتن پارامترهایی (ضرایب) برای ترکیب خطی ویژگیهای ورودی است. به نحوی که تخمین احتمال تعلق به دستهها به بهترین شکل انجام شود. برای یادگیری این پارامترها، اغلب از روشهای بهینهسازی مانند روش گرادیان کاهشی استفاده میشود. رگرسیون لجستیک در مسائل دستهبندی دودویی (دو دسته) و چنددستهای (بیش از دو دسته) مورد استفاده قرار میگیرد و به دلیل عملکرد خوب و قابلیت تعامل با ترکیبات خطی و غیرخطی از محبوبیت بالایی برخوردار است.
درخت تصمیم از الگوریتم های یادگیری ماشین
الگوریتم درخت تصمیم یکی از پرکاربردترین و قابل فهمترین الگوریتم های یادگیری ماشین است که برای مسائل دستهبندی و پیشبینی استفاده میشود. این الگوریتم به صورت یک ساختار درختی تصمیمگیری را ایجاد میکند که از سوالات بله/خیر برای تقسیم دادهها به دستههای مختلف استفاده میکند.
درخت تصمیم چندین گام دارد. در هر مرحله، الگوریتم بر اساس ویژگیهای دادهها، یک سوال میسازد و به ازای آن سوال دادهها را به دو دسته تقسیم میکند. این تقسیمبندی مکررا انجام می شود. در نهایت به برگههای درخت میرسیم که هر برگه یک تصمیم نهایی یا پیشبینی دارد.
یکی از مزیتهای درخت تصمیم، قابلیت تفسیر و فهمپذیری آن است. همچنین، این الگوریتم به طور طبیعی قادر به مدلسازی روابط غیرخطی و تعاملی در دادهها است. با این حال، در مواردی ممکن است به دلیل تمایل به تقسیم تصمیمات به صورت دودویی (بله/خیر)، نتواند مسائل پیچیدهتر را به خوبی مدل کند. از این رو معمولا ترکیبی از درختهای تصمیم (مانند انبوه درختی یا جنگل تصادفی) در مسائل سخت کاربرد دارد.
الگوریتم خوشه بندی
الگوریتم خوشه بندی از الگوریتم های یادگیری ماشین است که به منظور گروهبندی دادهها به دستههای مختلف بر اساس شباهتها و الگوهای مشترک آنها استفاده میشوند. هدف اصلی این الگوریتمها تقسیم دادهها به گروههایی به گونهای است که دادههای هر گروه با یکدیگر شبیهتر و دادههای گروهها با یکدیگر متفاوتتر باشند.
چند نمونه از الگوریتمهای خوشهبندی شامل موارد زیر میشوند:
- K-Means: در این الگوریتم، دادهها به تعداد k گروه تقسیم میشوند، که k تعداد خوشهها را مشخص میکند. ابتدا مراکز تصادفی برای خوشهها انتخاب میشود. سپس دادهها به نزدیکترین مرکز خوشه تخصیص داده میشوند. سپس مراکز خوشهها به میانگین دادههای موجود در هر خوشه بهروزرسانی میشوند تا به تدریج مراکز به موقعیتهای بهتری همگرا شوند.
- Hierarchical Clustering (خوشهبندی سلسلهمراتبی): در این روش، دادهها در یک ساختار سلسلهمراتبی از خوشهها قرار میگیرند. این سلسلهمراتب از درخت خوشهبندی نمایش داده میشود و با تقسیم و ادغام خوشهها به شکل مکرر، ساختار سلسلهمراتبی تکامل مییابد.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): این الگوریتم بر اساس چگالی نقاط در نزدیکی یکدیگر عمل میکند. این الگوریتم میتواند خوشههای با اشکال مختلف را تشخیص دهد و همچنین دادههای نویز را هم تشخیص دهد.
- Gaussian Mixture Model (GMM): این الگوریتم فرض میکند که دادهها از توزیعهای گوسی ترکیب شدهاند. با تعیین تعداد توزیعهای گوسی و پارامترهای آنها، خوشهبندی انجام میشود.
این الگوریتمها تنها چند نمونه از مجموعهای از الگوریتمهای خوشهبندی هستند که بسته به نوع دادهها و مسئله مورد نظر، انتخاب میشوند.
الگوریتم جنگل تصادفی
الگوریتم جنگل تصادفی (Random Forest) یکی از قدرتمندترین و محبوبترین الگوریتم های یادگیری ماشین است که برای مسائل دستهبندی و رگرسیون به کار میرود. این الگوریتم از ترکیب چندین درخت تصمیم ساخته شده با استفاده از تکنیکی به نام “تصادف” استفاده میکند.
فرآیند کار الگوریتم جنگل تصادفی به این شکل است:
- تصادفی ساختن زیرمجموعهها: از دادههای آموزشی تعداد زیرمجموعههای تصادفی با جایگذاری (bootstrap samples) انتخاب میشود. این زیرمجموعهها برای ساخت هر درخت تصمیم مورد استفاده قرار میگیرند.
- ساخت درختهای تصمیم: برای هر زیرمجموعه، یک درخت تصمیم با اصول مشابه الگوریتم درخت تصمیم ساخته میشود. این درختها معمولاً عمق کمتری دارند تا از بیشبرازش (over fitting) جلوگیری شود.
- تصمیمگیری ترکیبی: پس از ساخت همه درختها، وقتی یک نمونه جدید وارد میشود، هر یک از درختها به طور جداگانه برروی آن تصمیم میگیرند. سپس با اکثریت تصمیمها به عنوان خروجی نهایی انتخاب میشود.
الگوریتم جنگل تصادفی به دلیل ترکیب تصمیمهای چندین درخت، از بیشبرازش محافظت میکند و قدرت پیشبینی خوبی دارد. همچنین، این الگوریتم میتواند با مدلهای خطی و غیرخطی مختلف ترکیب شود و برای مسائل مختلف مورد استفاده قرار گیرد.
الگوریتم Naive Bayes
الگوریتم Naive Bayes یکی از محبوب ترین الگوریتم های یادگیری ماشین است که به عنوان یک مدل دستهبندی مورد استفاده قرار میگیرد. این الگوریتم بر مبنای تئوری احتمال و قاعده بیز میکارد و مخصوصاً برای مسائل دستهبندی متن و متغیرهای کیفی (کتگوریکال) مناسب است.
نام “Naive Bayes” که به معنی “سادهپندار” است، فرض میکند که ویژگیهای ورودی (در واقع ویژگیهایی که به مدل داده می شوند) مستقل از یکدیگر هستند. در حالی که در واقعیت ممکن است این استقلال وجود نداشته باشد. با این حال، این فرض سادهپندار در بسیاری از موارد عملی برای مسائل متغیرهای کیفی، به خوبی کار میکند.
نحوه کار اصلی الگوریتم Naive Bayes به این صورت است:
- محاسبه احتمالات پیشین (Prior Probabilities): ابتدا احتمالات پیشین برای هر دسته از دادهها محاسبه میشود.
- محاسبه احتمالات شرطی (Conditional Probabilities): برای هر ویژگی و هر دسته، احتمال شرطی محاسبه میشود. که نشان دهنده احتمال داده شدن ویژگیها به شرط داشتن دسته مورد نظر است.
- محاسبه احتمال پیشین به شرط دادهها (Posterior Probabilities): با استفاده از احتمالات پیشین و احتمالات شرطی، احتمال پیشین به شرط داشتن دادهها محاسبه میشود.
- تصمیمگیری: با مقایسه احتمالات پیشین به شرط دادهها برای هر دسته، دستهای که احتمال پیشین به شرط داشتن دادهها بیشتر باشد، به عنوان پیشبینی نهایی انتخاب میشود.
الگوریتم Naive Bayes به دلیل سرعت بالا و عملکرد خوب در مسائل متنی (مانند تشخیص اسپم یا دستهبندی متن) مورد استفاده قرار میگیرد. با این حال، اگر تئوری احتمالیات در مورد ویژگیها برقرار نباشد، ممکن است نتایج نامطلوبی داشته باشد.
الگوریتم کاهش ابعاد
الگوریتم کاهش ابعاد یکی از الگوریتم های یادگیری ماشین است که برای کاهش تعداد ویژگیها یا ابعاد دادهها به منظور افزایش کارایی و کاهش پیچیدگی محاسباتی استفاده میشود. این الگوریتمها به طور خاص برای مواجهه با مسائلی که دارای تعداد زیاد ویژگی یا متغیرهای مستقل هستند، مفید هستند.
یکی از الگوریتمهای کاهش ابعاد معروف تر PCA (Principal Component Analysis) است. در این الگوریتم، ویژگیها به ویژگیهای جدید تبدیل میشوند که تغییرات بیشتری در دادهها را در ابتدای محورهای جدید نشان میدهند. این محورها “اجزای اصلی” یا “مؤلفههای اصلی” هستند. ترکیبی از اجزای اصلی با تغییرات بیشتر در دادهها به ویژگیهای جدید منجر میشود که کمترین اطلاعات مهم را از دادهها از دست دادهاند.
یکی از مزایای کاهش ابعاد این است که میتواند به کاهش بعد ویژگیها و افزایش سرعت محاسباتی منجر شود. همچنین، میتواند به بهبود عملکرد مدلهای یادگیری ماشین در مواردی که تعداد زیادی ویژگی داریم کمک کند. با این حال، در برخی موارد، استفاده از کاهش ابعاد ممکن است باعث از دست دادن بخشی از اطلاعات مهم در دادهها شود.
الگوریتم گرادیان تقویتی
الگوریتم گرادیان تقویتی (Gradient Boosting) یکی از قدرتمندترین الگوریتم های یادگیری ماشین است که برای مسائل دستهبندی و پیشبینی استفاده میشود. این الگوریتم از ترکیب چندین مدل ضعیف (معمولاً درخت تصمیم) به منظور ساخت یک مدل قویتر استفاده میکند.
عملکرد اصلی الگوریتم گرادیان تقویتی به این شکل است:
- ساخت مدل اولیه: ابتدا یک مدل ضعیف (مثلا یک درخت تصمیم کوچک) ساخته میشود تا به عنوان مدل اولیه استفاده شود.
- محاسبه خطاها: میزان خطاهای مدل اولیه بر روی دادههای آموزش محاسبه میشود.
- ساخت مدل بعدی با توجه به خطاها: یک مدل جدید ضعیف ساخته میشود که سعی میکند خطاهای مدل قبلی را کم کند. برای این کار، این مدل به نحوی تنظیم میشود که در نقاطی که مدل قبلی خطا کرده است، بهتر عمل کند.
- ترکیب مدلها: مدلهای ضعیفی که ساخته شدند، در مراحل قبل به یکدیگر اضافه میشوند تا مدل نهایی تشکیل شود. این ترکیب معمولا با جمع وزندار نتایج مدلهای ضعیف صورت میگیرد.
- تکرار مراحل 2 تا 4: مراحل 2 تا 4 به تعداد تکرارهای مشخصی تکرار میشوند. هر بار مدل جدید سعی میکند خطاهای مدلهای قبلی را کم کند و به مرور مدل نهایی بهبود پیدا میکند.
الگوریتم گرادیان تقویتی به دلیل عملکرد قدرتمند و قابلیت تطبیق با مسائل مختلف محبوبیت بالایی دارد. با مراجعه به آکادمی تخصصی هوش مصنوعی، به دنیایی از امکانات و فرصتهای مطالعه در زمینه هوش مصنوعی وارد میشوید.




دیدگاهتان را بنویسید