ماشین بردار پشتیبان
ماشین بردار پشتیبان (Support Vector Machine یا SVM) یکی از الگوریتمهای مهم و محبوب در حوزه یادگیری ماشین است که برای مسائل دستهبندی و رگرسیون استفاده میشود. SVM از برخی مفاهیم ریاضی و هندسی قوی برای تفکیک دادهها و پیدا کردن مرزهای تصمیمگیری بهره میبرد. SVM یکی از الگوریتمهای برجسته یادگیری ماشین است که به عنوان یک ابزار قوی در تفکیک دادهها و دستهبندی با دقت بالا شناخته میشود. این الگوریتم با تعیین یک مرز تصمیمگیری مناسب به دادهها امکان میدهد مسائل مختلف را حل کند. کاربرد هوش مصنوعی بسیار فراوان است. کاربرد هوش مصنوعی در صنعت، کاربرد هوش مصنوعی در کشاورزی و یادگیری عمیق مشاهده میکنید. برای آموزش بیشتر در رابطه با انواع هوش مصنوعی، میتوانید به آکادمی تخصصی هوش مصنوعی مهسا مراجعه کنید. در ادامه در رابطه با ماشین بردار پشتیبان بیشتر توضیح میدهیم.
ماشین بردار پشتیبان چیست؟
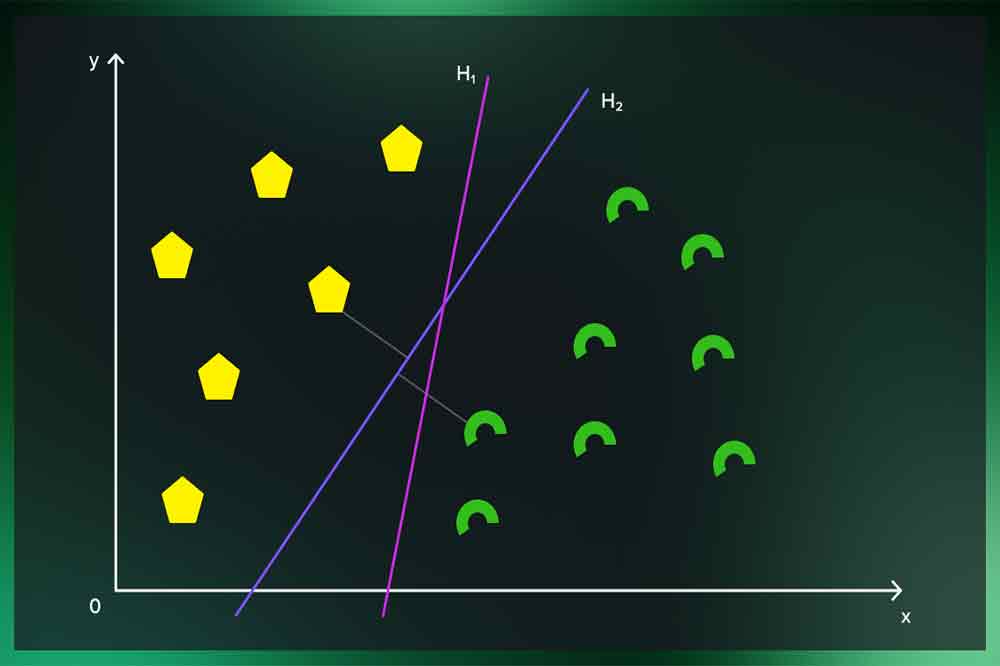
ماشین بردار پشتیبان یک الگوریتم یادگیری ماشین است که برای مسائل مختلفی از جمله دستهبندی و رگرسیون استفاده میشود. این الگوریتم با استفاده از دادههای آموزشی، یک مدل ریاضی ایجاد میکند که به تشخیص الگوها و تفکیک دستهها کمک میکند. یکی از ویژگیهای مهم ماشین بردار پشتیبان این است که تلاش میکند یک صفحه (برای دستهبندی دو کلاسه) یا فضایی چند بعدی (برای دستهبندی چند کلاسه) را به نحوی انتخاب کند که بیشتر دادههای آموزشی از آن طرفین قرار بگیرند و میان آن صفحه یا فضا با فاصله حداکثری قرار گیرند. این فاصله به نام حاشیه (margin) شناخته میشود.
علاوه بر این، ماشین بردار پشتیبان از مفهوم پشتیبانگیری (support vector) استفاده میکند که دادههای مهم و مرزی در دستهبندی را مشخص میکنند. این الگوریتم معمولاً با استفاده از یک تابع هسته (kernel function) نیز قابل انعطافسازی است تا با دادههایی که به صورت غیرخطی قابل تفکیک هستند نیز بتواند کار کند. ماشین بردار پشتیبان به عنوان یکی از الگوریتمهای قوی و معمولا دقیق در دستهبندی دادهها معروف است.
تعریف ماشین لرنینگ
یادگیری ماشین (Machine Learning) یک زیرزمینه مهم و متنوع از هوش مصنوعی (AI) است که به ماشینها و سیستمهای کامپیوتری امکان میدهد از دادهها یاد بگیرند و بدون برنامهریزی صریح بتوانند الگوها و اطلاعات را استخراج کنند. اصطلاح “ماشین لرنینگ” به توصیف روشها و الگوریتمهایی اطلاق میشود که از دادههای ورودی به یادگیری مدلهای پیشبینی و تصمیمگیری استفاده میکنند.
مهمترین وظیفه یادگیری ماشین عبارتند از:
- دستهبندی (Classification): تفکیک دادهها به گروهها یا دستههای مختلف. به عنوان مثال، تشخیص ایمیلهای هرزنامه از ایمیلهای اصلی یک مسئله دستهبندی است.
- رگرسیون (Regression): پیشبینی یک مقدار پیوسته بر اساس دادههای ورودی. برای مثال، پیشبینی قیمت یک ملک بر اساس ویژگیهای آن
- خوشهبندی (Clustering): گروهبندی دادهها به گروههای مشابه بدون دانش از دستهها. به عنوان مثال، دستهبندی مشتریان بر اساس رفتارهای خرید آنها
- یادگیری تقویتی (Reinforcement Learning): یادگیری به صورت تعاملی از طریق تجربه و پاداش. به عنوان مثال، آموزش یک ربات برای بازی یک بازی و به دست آوردن بیشترین پاداش
در یادگیری ماشین، مدلهای مختلفی مانند شبکههای عصبی، درخت تصمیم و ماشین بردار پشتیبان برای حل مسائل مورد استفاده قرار میگیرند. این مدلها با استفاده از دادههای آموزشی به طور خودکار تنظیم میشوند و سپس قادر به پیشبینی و تصمیمگیری بر اساس دادههای جدید هستند.
کاربرد ماشین بردار پشتیبان در یادگیری ماشین
ماشین بردار پشتیبان (SVM) یکی از الگوریتمهای مهم در یادگیری ماشین است که در موارد مختلف کاربرد دارد. این الگوریتم به خصوص در مسائل دستهبندی مورد توجه قرار میگیرد. برخی از کاربردهای اصلی ماشین بردار پشتیبان در یادگیری ماشین عبارتند از:
- دستهبندی دو کلاسه: SVM معمولا برای دستهبندی دو کلاسه (دارای دو دسته یا گروه) استفاده میشود. به عنوان مثال، تشخیص ایمیلهای هرزنامه از ایمیلهای اصلی، تشخیص بیماریهای خاص از تستهای پزشکی، یا تشخیص محصولات معیوب از محصولات قابل قبول
- دستهبندی چند کلاسه: SVM میتواند به صورت مستقیم برای دستهبندی چند کلاسه (دارای بیش از دو دسته) نیز استفاده شود. این با استفاده از ترکیب تعدادی SVM دو کلاسه انجام میشود.
- پشتیبانگیری از دادهها: SVM مدلهای پشتیبانی (support vectors) را تشخیص داده و استفاده از آنها میکند. این مدلها نقاط مهم در تفکیک دستهها هستند و به طور کلی موثرترین دادهها را شناسایی میکنند.
- دادههای با ابعاد بالا (High-Dimensional Data) : SVM برای مسائلی که دادههای با ابعاد بالا دارند (مثل تصویربرداری و پردازش متن) مناسب است و معمولاً به خوبی عمل میکند.
- کاربردهای تشخیص تصویری: SVM میتواند در تشخیص و تصویربرداری الگوها و ویژگیهای تصویری مانند تشخیص چهرهها، شناسایی اشیاء و اجسام، و تشخیص متن در تصاویر مورد استفاده قرار گیرد.
- بیوانفورماتیک: در بیوانفورماتیک، SVM برای پیشبینی ویژگیهای مولکولی، تشخیص پروتئینها و ترتیب DNA مورد استفاده قرار میگیرد.
در کل، SVM به عنوان یک الگوریتم قوی و کارآمد در یادگیری ماشین با دقت و توانایی در مسائل مختلف شناخته میشود.
کاربردهای دیگر SVM
ماشین بردار پشتیبان (SVM) کاربردهای متعددی در مختلف زمینهها دارد. این الگوریتم یادگیری ماشینی به عنوان یک ابزار قوی در دستهبندی و تصمیمگیری با دقت بالا شناخته میشود. برخی از کاربردهای مهم ماشین بردار پشتیبان عبارتند از:
- تشخیص دستنوشته و حروف الفبا: SVM به عنوان یکی از روشهای موثر در تشخیص و تشخیص دستنوشتهها و حروف الفبا در تصاویر استفاده میشود، از جمله تشخیص خطوط و اسکنها
- تشخیص اشیا و تصویربرداری: SVM در بینایی ماشین و تشخیص اشیاء در تصاویر کاربردهای بسیاری دارد. به عنوان مثال، تشخیص ماشینها در تصاویر ترافیک یا تشخیص اجسام در تصاویر پزشکی
- تشخیص موسیقی و صدا: SVM برای تشخیص الگوها و ویژگیهای موسیقی یا صدا مورد استفاده قرار میگیرد، از جمله تشخیص نوازندگی و آواز
- تشخیص اسپم ایمیل: SVM میتواند برای تشخیص ایمیلهای هرزنامه از ایمیلهای معمولی به کار رود. این یک کاربرد متداول در فیلترهای اسپم ایمیل است.
- پیشبینی سریزمانی: SVM میتواند برای پیشبینی سریزمانی مورد استفاده قرار گیرد، مانند پیشبینی قیمتهای بازارهای مالی یا پیشبینی ترافیک راهها
- ترجمه ماشینی: در ترجمه ماشینی، SVM ممکن است برای تشخیص و ترجمه متن از یک زبان به زبان دیگر به کار رود.
- تجزیه و تحلیل متن: SVM میتواند در تجزیه و تحلیل متن و استخراج اطلاعات از متنهای بزرگ مفید باشد، مثلاً در تحلیل احساسات مشتریان
- پزشکی: SVM در تشخیص بیماریها، تشخیص تصاویر پزشکی، و پیشبینی ترتیب DNA در پژوهشهای بیولوژیکی کاربردهای زیادی دارد.
این فقط چند مثال از کاربردهای SVM است، و این الگوریتم در صنایع مختلف از جمله علوم داده، بینایی ماشین، پزشکی، مالی، و بسیاری زمینههای دیگر مورد استفاده قرار میگیرد.
نحوه کار SVM
ماشین بردار پشتیبان (SVM) برای دستهبندی دادهها عمل میکند و کارکرد آن به شرح زیر است:
- تعیین ویژگیها: ابتدا برای هر نمونه داده، ویژگیهای مورد نظر را مشخص میکنیم. این ویژگیها معمولا به عنوان متغیرهای ورودی یا ویژگیهای ورودی به مدل SVM وارد میشوند. برای مثال، در مسئله تشخیص ایمیلهای هرزنامه، ویژگیها میتوانند تعداد کلمات موجود در ایمیل یا تعداد اسپمواژگان باشند.
- تشکیل دستهها: سپس دادهها به دستههای مختلف تقسیم میشوند. SVM به عنوان مثال برای دستهبندی دو کلاسه (دسته مثبت و منفی) استفاده میشود. در مسئله تشخیص ایمیلهای هرزنامه، دسته مثبت ممکن است ایمیلهای هرزنامه باشند و دسته منفی ایمیلهای اصلی.
- تشکیل مدل: SVM سعی میکند یک صفحه (در مسائل دو کلاسه) یا فضایی چند بعدی (در مسائل چند کلاسه) را به نحوی انتخاب کند که دادههای مثبت و منفی از آن طرفین قرار بگیرند و میان آن حاشیه حداکثری داشته باشند. این صفحه یا فضا به عنوان “صفحه جداکننده” شناخته میشود.
- پشتیبانگیری: SVM مهمترین دادهها را که به عنوان پشتیبانها یا دادههای پشتیبان شناخته میشوند، تشخیص میدهد. این دادهها در محلی که به حاشیه نزدیکترینند و در تعیین مکان صفحه جداکننده موثرترین هستند، قرار میگیرند.
- پیشبینی: بعد از آموزش، SVM قادر به پیشبینی تصمیمها بر اساس ویژگیها برای دادههای جدید است. اگر نمونه جدید به یک طرف خاص از صفحه جداکننده افتد، آن نمونه به آن طرف اختصاص مییابد.
کارکرد SVM به تلاش برای تعیین صفحه یا فضایی که دادهها را به نحوی تفکیک میکند و به حاشیه بیشتری دست پیدا میکند، برمیگردد. این به SVM امکان مدلسازی دقیق و عملکرد خوب در مسائل دستهبندی را میدهد.
استفاده از SVM برای حال مساله
برای استفاده از ماشین بردار پشتیبان (SVM) برای حل یک مساله، شما نیاز دارید به مراحل زیر پیش بروید:
- جمعآوری و پیشپردازش دادهها: جمعآوری دادههایی که به مساله مربوط هستند. پیشپردازش دادهها از جمله حذف دادههای تکراری، پرت، و ناکارآمد، مقیاسدادن ویژگیها، و تبدیل دادههای متنی به بردارهای عددی میتواند مورد نیاز باشد.
- انتخاب مدل SVM: تعیین نوع مساله (دستهبندی دو کلاسه، دستهبندی چند کلاسه، رگرسیون، و غیره) و انتخاب نوع SVM مناسب (مانند SVM خطی یا SVM غیرخطی با استفاده از توابع هسته).
- آموزش مدل SVM: تقسیم دادهها به دو مجموعه: دادههای آموزشی و دادههای آزمایش (یا اعتبارسنجی)، آموزش مدل SVM بر روی دادههای آموزشی. در این مرحله، ماشین بردار پشتیبان سعی میکند مدلی ایجاد کند که دادههای آموزشی را به خوبی تفکیک کند.
- تنظیم پارامترها: تنظیم پارامترهای مدل SVM مانند پارامترهای توابع هسته و مقادیر مربوط به مقادیر خطا (مانند C در SVM خطی) با استفاده از روشهای انتخاب بهترین پارامترها (مانند جستجوی خطی یا جستجوی خودکار).
- ارزیابی مدل: استفاده از دادههای آزمایش یا اعتبارسنجی برای ارزیابی کارایی مدل SVM. معیارهایی مانند دقت، بازیابی، دقت پیشبینی، و منحنی مشخصه عملکرد (ROC curve) میتوانند برای این منظور مورد استفاده قرار گیرند.
- پیشبینی و استفاده از مدل: بعد از آموزش و ارزیابی مدل، شما میتوانید از مدل SVM برای پیشبینی و تصمیمگیری بر روی دادههای جدید استفاده کنید.
- تنظیم و بهبود مدل: در صورتی که عملکرد مدل SVM ناکامی بود یا نیاز به بهبود داشت، میتوانید با تغییر پارامترها یا استفاده از مدلهای SVM متفاوت تلاش کنید.
برای موفقیت در استفاده از SVM، مهم است که دادههای خوبی را جمعآوری و پیشپردازش کنید و مدل را با دقت تنظیم کنید. همچنین، در انتخاب نوع SVM و توابع هسته به دقت توجه کنید، زیرا این انتخابها به شدت وابسته به مساله مورد نظر شما هستند.
SVM غیر خطی
ماشین بردار پشتیبان غیر خطی (Non-Linear Support Vector Machine یا Non-Linear SVM) یک نوع از ماشین بردار پشتیبان (SVM) است که برای مسائلی که دادهها به صورت غیرخطی تفکیک میشوند، استفاده میشود. در مقابل SVM خطی که از صفحه جداکننده خطی بهره میبرد، SVM غیر خطی از توابع هسته (Kernel Functions) بهره میبرد تا بتواند الگوها و تفکیکهای غیرخطی را نمایش دهد.
عملکرد SVM غیر خطی به این صورت است:
- انتخاب تابع هسته: ابتدا باید یک تابع هسته مناسب انتخاب کرد. تابع هسته یک تابع ریاضی است که ویژگیهای دادهها را به فضایی با ابعاد بالاتر تبدیل میکند. این تبدیل به دادهها امکان تفکیک در فضای با ابعاد بالاتر را میدهد.
- آموزش مدل: سپس با استفاده از تابع هسته منتخب، مدل SVM غیر خطی روی دادههای آموزشی آموزش داده میشود. مدل سعی میکند یک مرز تصمیمگیری پیچیدهتر و غیرخطی را در فضای جدید تعیین کند تا دادههای مثبت و منفی را به صورت دقیق تفکیک کند.
- پیشبینی: بعد از آموزش، مدل SVM غیر خطی قادر به پیشبینی دستهبندی دادههای جدید در فضای با ابعاد بالا است. این پیشبینیها بر اساس مرز تصمیمگیری غیرخطی انجام میشوند.
توابع هسته متداول در SVM غیر خطی عبارتند از:
- تابع هسته چندجملهای (Polynomial Kernel): از آن برای مدلسازی الگوها با تفکیک غیرخطی استفاده میشود.
- تابع هسته گاوسی (Gaussian Kernel): یا تابع هسته RBF (Radial Basis Function) به عنوان یکی از معروفترین توابع هسته غیر خطی استفاده میشود.
- تابع هسته سیگموئید (Sigmoid Kernel): معمولا در مسائل مشخصی که تفکیک غیرخطی مورد نیاز دارند به کار میرود.
SVM غیر خطی به عنوان یک الگوریتم قوی در مسائلی که تفکیک غیرخطی دادهها مورد نیاز است، شناخته میشود، از جمله در بینایی ماشین، پردازش متن، تشخیص الگوها و دادهکاوی به کار میرود.
SVM خطی
ماشین بردار پشتیبان خطی (Linear Support Vector Machine یا Linear SVM) یک نوع از ماشین بردار پشتیبان (SVM) است که برای مسائل دستهبندی دو کلاسه و چند کلاسه استفاده میشود. این نوع SVM از تابع هسته خطی بهره میبرد که به عنوان یک صفحه جداکننده عمل میکند. در واقع، SVM خطی سعی دارد یک صفحه (در بعضی موارد فضای چند بعدی) را به نحوی انتخاب کند که دادههای دو گروه یا کلاس را به خوبی از یکدیگر جدا کند.
برای دستهبندی نمونهها، SVM خطی از یک تابع تصمیم خطی استفاده میکند که در واقع معادله مستقیم یک بعدی (برای دستهبندی دو کلاسه) یا معادله صفحه (برای دستهبندی چند کلاسه) است. این تابع تصمیم بر اساس ویژگیهای ورودی (متغیرهای مستقل) مشخص میکند که نمونهها به کدام گروه تعلق دارند.
مزیت اصلی ماشین بردار پشتیبان خطی این است که در مواجهه با مسائل با مقدار بالایی از ویژگیها یا دادههای با ابعاد بالا به خوبی عمل میکند. همچنین، این نوع SVM به دلیل سادگی محاسباتی خود به عنوان یک روش ابتدایی برای دستهبندی مورد استفاده قرار میگیرد. به طور خلاصه، SVM خطی یک الگوریتم دستهبندی قوی است که از تابع تصمیم خطی برای جداکنندگی دادهها استفاده میکند و در مسائل دستهبندی مختلف مورد استفاده قرار میگیرد، به خصوص در مواردی که دادهها به خوبی توسط یک صفحه جدا نشوند. کاربرد ماشین لرنینگ بسیار گسترده است. به طوری که، کاربرد ماشین لرنینگ در عمران، کاربرد ماشین لرنینگ در مهندسی برق را مشاهده میکنید. با مراجعه به آکادمی تخصصی هوش مصنوعی مهسا میتوانید به عالمی در این عرصه تبدیل شده و در حوزه هوش مصنوعی فعالیت کنید.




دیدگاهتان را بنویسید